Load data from a cloud storage or a file system
This tutorial is for you if you need to load data files like JSONL, CSV, and Parquet from either Cloud Storage (e.g., AWS S3, Google Cloud Storage, Google Drive, Azure Blob Storage), a remote (SFTP), or a local file system.
What you will learn
- How to set up a file system or cloud storage as a data source
- Configuration basics for file systems and cloud storage
- Loading methods
- Incremental loading of data from file systems or cloud storage
- How to load data of any type
0. Prerequisites
- Python 3.9 or higher installed
- Virtual environment set up
dltinstalled. Follow the instructions in the installation guide to create a new virtual environment and install dlt.
1. Setting up a new project
To help you get started quickly, dlt provides some handy CLI commands. One of these commands will help you set up a new dlt project:
dlt init filesystem duckdb
This command creates a project that loads data from a file system into a DuckDB database. You can easily switch out duckdb for any other supported destinations. After running this command, your project will have the following structure:
filesystem_pipeline.py
requirements.txt
.dlt/
config.toml
secrets.toml
Here’s what each file does:
filesystem_pipeline.py: This is the main script where you'll define your data pipeline. It contains several different examples of loading data from the filesystem source.requirements.txt: This file lists all the Python dependencies required for your project..dlt/: This directory contains the configuration files for your project:secrets.toml: This file stores your API keys, tokens, and other sensitive information.config.toml: This file contains the configuration settings for your dlt project.
When deploying your pipeline in a production environment, managing all configurations with files might not be convenient. In this case, we recommend you use environment variables to store secrets and configs instead. Read more about configuration providers available in dlt.
2. Creating the pipeline
The filesystem source provides users with building blocks for loading data from any type of files. You can break down the data extraction into two steps:
- Listing the files in the bucket/directory.
- Reading the files and yielding records.
dlt's filesystem source includes several resources:
- The
filesystemresource lists files in the directory or bucket. - Several readers resources (
read_csv,read_parquet,read_jsonl) read files and yield the records. These resources have a special type; they are called transformers. Transformers expect items from another resource. In this particular case, transformers expect aFileItemobject and transform it into multiple records.
Let's initialize a source and create a pipeline for loading CSV files from Google Cloud Storage to DuckDB. You can replace the code from filesystem_pipeline.py with the following:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
files = filesystem(bucket_url="gs://filesystem-tutorial", file_glob="encounters*.csv")
reader = (files | read_csv()).with_name("encounters")
pipeline = dlt.pipeline(pipeline_name="hospital_data_pipeline", dataset_name="hospital_data", destination="duckdb")
info = pipeline.run(reader)
print(info)
What's happening in the snippet above?
- We import the
filesystemresource and initialize it with a bucket URL (gs://filesystem-tutorial) and thefile_globparameter. dlt usesfile_globto filter file names in the bucket.filesystemreturns a generator object. - We pipe the file names yielded by the filesystem resource to the transformer resource
read_csvto read each file and iterate over records from the file. We name this transformer resource"encounters"using thewith_name()method. dlt will use the resource name"encounters"as a table name when loading the data.
A transformer in dlt is a special type of resource that processes each record from another resource. This lets you chain multiple resources together.
- We create the dlt pipeline, configuring it with the name
hospital_data_pipelineand DuckDB as the destination. - We call
pipeline.run(). This is where the underlying generators are iterated:
- dlt retrieves remote data,
- normalizes data,
- creates or updates the table in the destination,
- loads the extracted data into the destination.
print(info)outputs the pipeline running stats we get frompipeline.run().
3. Configuring the filesystem source
In this tutorial, we will work with the publicly accessed dataset Hospital Patient Records, which contains synthetic electronic health care records. You can use the exact credentials from this tutorial to load this dataset from GCP.
Citation
Next, we need to configure the connection. Specifically, we’ll set the bucket URL and credentials. This example uses Google Cloud Storage. For other cloud storage services, see the Filesystem configuration section.
Let's specify the bucket URL and credentials. We can do this using the following methods:
- TOML config provider
- Environment variables
- In the code
# secrets.toml
[sources.filesystem.credentials]
client_email = "public-access@dlthub-sandbox.iam.gserviceaccount.com"
project_id = "dlthub-sandbox"
private_key = "-----BEGIN PRIVATE KEY-----\nMIIEvAIBADANBgkqhkiG9w0BAQEFAASCBKYwggSiAgEAAoIBAQDGWsVHJRjliojx\nTo+j1qu+x8PzC5ZHZrMx6e8OD6tO8uxMyl65ByW/4FZkVXkS4SF/UYPigGN+rel4\nFmySTbP9orva4t3Pk1B9YSvQMB7V5IktmTIW9Wmdmn5Al8Owb1RehgIidm1EX/Z9\nLr09oLpO6+jUu9RIP2Lf2mVQ6tvkgl7UOdpdGACSNGzRiZgVZDOaDIgH0Tl4UWmK\n6iPxhwZy9YC2B1beLB/NU+F6DUykrEpBzCFQTqFoTUcuDAEvuvpU9JrU2iBMiOGw\nuP3TYSiudhBjmauEUWaMiqWAgFeX5ft1vc7/QWLdI//SAjaiTAu6pTer29Q0b6/5\niGh0jRXpAgMBAAECggEAL8G9C9MXunRvYkH6/YR7F1T7jbH1fb1xWYwsXWNSaJC+\nagKzabMZ2KfHxSJ7IxuHOCNFMKyex+pRcvNbMqJ4upGKzzmeFBMw5u8VYGulkPQU\nPyFKWRK/Wg3PZffkSr+TPargKrH+vt6n9x3gvEzNbqEIDugmRTrVsHXhvOi/BrYc\nWhppHSVQidWZi5KVwDEPJjDQiHEcYI/vfIy1WhZ8VuPAaE5nMZ1m7gTdeaWWKIAj\n/p2ZkLgRdCY8vNkfaNDAxDbvH+CMuTtOw55GydzsYYiofANS6xZ8CedGkYaGi82f\nqGdLghX61Sg3UAb5SI36T/9XbuCpTf3B/SMV20ew8QKBgQDm2yUxL71UqI/xK9LS\nHWnqfHpKmHZ+U9yLvp3v79tM8XueSRKBTJJ4H+UvVQrXlypT7cUEE+sGpTrCcDGL\nm8irtdUmMvdi7AnRBgmWdYKig/kgajLOUrjXqFt/BcFgqMyTfzqPt3xdp6F3rSEK\nHE6PQ8I3pJ0BJOSJRa6Iw2VH1QKBgQDb9WbVFjYwTIKJOV4J2plTK581H8PI9FSt\nUASXcoMTixybegk8beGdwfm2TkyF/UMzCvHfuaUhf+S0GS5Zk31Wkmh1YbmFU4Q9\nm9K/3eoaqF7CohpigB0wJw4HfqNh6Qt+nICOMCv++gw7+/UwfV72dCqr0lpzfX5F\nAsez8igTxQKBgDsq/axOnQr+rO3WGpGJwmS8BKfrzarxGXyjnV0qr51X4yQdfGWx\nV3T8T8RC2qWI8+tQ7IbwB/PLE3VURg6PHe6MixXgSDGNZ7KwBnMOqS23/3kEXwMs\nhn2Xg+PZeMeqW8yN9ldxYqmqViMTN32c5bGoXzXdtfPeHcjlGCerVOEFAoGADVPi\nRjkRUX3hTvVF6Gzxa2OyQuLI1y1O0C2QCakrngyI0Dblxl6WFBwDyHMYGepNnxMj\nsr2p7sy0C+GWuGDCcHNwluQz/Ish8SW28F8+5xyamUp/NMa0fg1vwS6AMdeQFbzf\n4T2z/MAj66KJqcV+8on5Z+3YAzVwaDgR56pdmU0CgYBo2KWcNWAhZ1Qa6sNrITLV\nGlxg6tWP3OredZrmKb1kj5Tk0V+EwVN+HnKzMalv6yyyK7SWq1Z6rvCye37vy27q\nD7xfuz0c0H+48uWJpdLcsxpTioopsRPayiVDKlHSe/Qa+MEjAG3ded5TJiC+5iSw\nxWJ51y0wpme0LWgzzoLbRw==\n-----END PRIVATE KEY-----\n"
# config.toml
[sources.filesystem]
bucket_url="gs://filesystem-tutorial"
export SOURCES__FILESYSTEM__CREDENTIALS__CLIENT_EMAIL="public-access@dlthub-sandbox.iam.gserviceaccount.com"
export SOURCES__FILESYSTEM__CREDENTIALS__PROJECT_ID="dlthub-sandbox"
export SOURCES__FILESYSTEM__CREDENTIALS__PRIVATE_KEY="-----BEGIN PRIVATE KEY-----\nMIIEvAIBADANBgkqhkiG9w0BAQEFAASCBKYwggSiAgEAAoIBAQDGWsVHJRjliojx\nTo+j1qu+x8PzC5ZHZrMx6e8OD6tO8uxMyl65ByW/4FZkVXkS4SF/UYPigGN+rel4\nFmySTbP9orva4t3Pk1B9YSvQMB7V5IktmTIW9Wmdmn5Al8Owb1RehgIidm1EX/Z9\nLr09oLpO6+jUu9RIP2Lf2mVQ6tvkgl7UOdpdGACSNGzRiZgVZDOaDIgH0Tl4UWmK\n6iPxhwZy9YC2B1beLB/NU+F6DUykrEpBzCFQTqFoTUcuDAEvuvpU9JrU2iBMiOGw\nuP3TYSiudhBjmauEUWaMiqWAgFeX5ft1vc7/QWLdI//SAjaiTAu6pTer29Q0b6/5\niGh0jRXpAgMBAAECggEAL8G9C9MXunRvYkH6/YR7F1T7jbH1fb1xWYwsXWNSaJC+\nagKzabMZ2KfHxSJ7IxuHOCNFMKyex+pRcvNbMqJ4upGKzzmeFBMw5u8VYGulkPQU\nPyFKWRK/Wg3PZffkSr+TPargKrH+vt6n9x3gvEzNbqEIDugmRTrVsHXhvOi/BrYc\nWhppHSVQidWZi5KVwDEPJjDQiHEcYI/vfIy1WhZ8VuPAaE5nMZ1m7gTdeaWWKIAj\n/p2ZkLgRdCY8vNkfaNDAxDbvH+CMuTtOw55GydzsYYiofANS6xZ8CedGkYaGi82f\nqGdLghX61Sg3UAb5SI36T/9XbuCpTf3B/SMV20ew8QKBgQDm2yUxL71UqI/xK9LS\nHWnqfHpKmHZ+U9yLvp3v79tM8XueSRKBTJJ4H+UvVQrXlypT7cUEE+sGpTrCcDGL\nm8irtdUmMvdi7AnRBgmWdYKig/kgajLOUrjXqFt/BcFgqMyTfzqPt3xdp6F3rSEK\nHE6PQ8I3pJ0BJOSJRa6Iw2VH1QKBgQDb9WbVFjYwTIKJOV4J2plTK581H8PI9FSt\nUASXcoMTixybegk8beGdwfm2TkyF/UMzCvHfuaUhf+S0GS5Zk31Wkmh1YbmFU4Q9\nm9K/3eoaqF7CohpigB0wJw4HfqNh6Qt+nICOMCv++gw7+/UwfV72dCqr0lpzfX5F\nAsez8igTxQKBgDsq/axOnQr+rO3WGpGJwmS8BKfrzarxGXyjnV0qr51X4yQdfGWx\nV3T8T8RC2qWI8+tQ7IbwB/PLE3VURg6PHe6MixXgSDGNZ7KwBnMOqS23/3kEXwMs\nhn2Xg+PZeMeqW8yN9ldxYqmqViMTN32c5bGoXzXdtfPeHcjlGCerVOEFAoGADVPi\nRjkRUX3hTvVF6Gzxa2OyQuLI1y1O0C2QCakrngyI0Dblxl6WFBwDyHMYGepNnxMj\nsr2p7sy0C+GWuGDCcHNwluQz/Ish8SW28F8+5xyamUp/NMa0fg1vwS6AMdeQFbzf\n4T2z/MAj66KJqcV+8on5Z+3YAzVwaDgR56pdmU0CgYBo2KWcNWAhZ1Qa6sNrITLV\nGlxg6tWP3OredZrmKb1kj5Tk0V+EwVN+HnKzMalv6yyyK7SWq1Z6rvCye37vy27q\nD7xfuz0c0H+48uWJpdLcsxpTioopsRPayiVDKlHSe/Qa+MEjAG3ded5TJiC+5iSw\nxWJ51y0wpme0LWgzzoLbRw==\n-----END PRIVATE KEY-----\n"
export SOURCES__FILESYSTEM__BUCKET_URL="gs://filesystem-tutorial"
import os
from dlt.common.configuration.specs import GcpClientCredentials
from dlt.sources.filesystem import filesystem, read_csv
files = filesystem(
bucket_url="gs://filesystem-tutorial",
# please, do not specify sensitive information directly in the code,
# instead, you can use env variables to get the credentials
credentials=GcpClientCredentials(
client_email="public-access@dlthub-sandbox.iam.gserviceaccount.com",
project_id="dlthub-sandbox",
private_key=os.environ["GCP_PRIVATE_KEY"] # type: ignore
),
file_glob="encounters*.csv") | read_csv()
As you can see, all parameters of filesystem can be specified directly in the code or taken from the configuration.
dlt supports more ways of authorizing with cloud storages, including identity-based and default credentials. To learn more about adding credentials to your pipeline, please refer to the Configuration and secrets section.
4. Running the pipeline
Let's verify that the pipeline is working as expected. Run the following command to execute the pipeline:
python filesystem_pipeline.py
You should see the output of the pipeline execution in the terminal. The output will also display the location of the DuckDB database file where the data is stored:
Pipeline hospital_data_pipeline load step completed in 4.11 seconds
1 load package(s) were loaded to destination duckdb and into dataset hospital_data
The duckdb destination used duckdb:////Users/vmishechk/PycharmProjects/dlt/hospital_data_pipeline.duckdb location to store data
Load package 1726074108.8017762 is LOADED and contains no failed jobs
5. Exploring the data
Now that the pipeline has run successfully, let's explore the data loaded into DuckDB. dlt comes with a built-in browser application that allows you to interact with the data. To enable it, run the following command:
pip install streamlit
Next, run the following command to start the data browser:
dlt pipeline hospital_data_pipeline show
The command opens a new browser window with the data browser application. hospital_data_pipeline is the name of the pipeline defined in the filesystem_pipeline.py file.
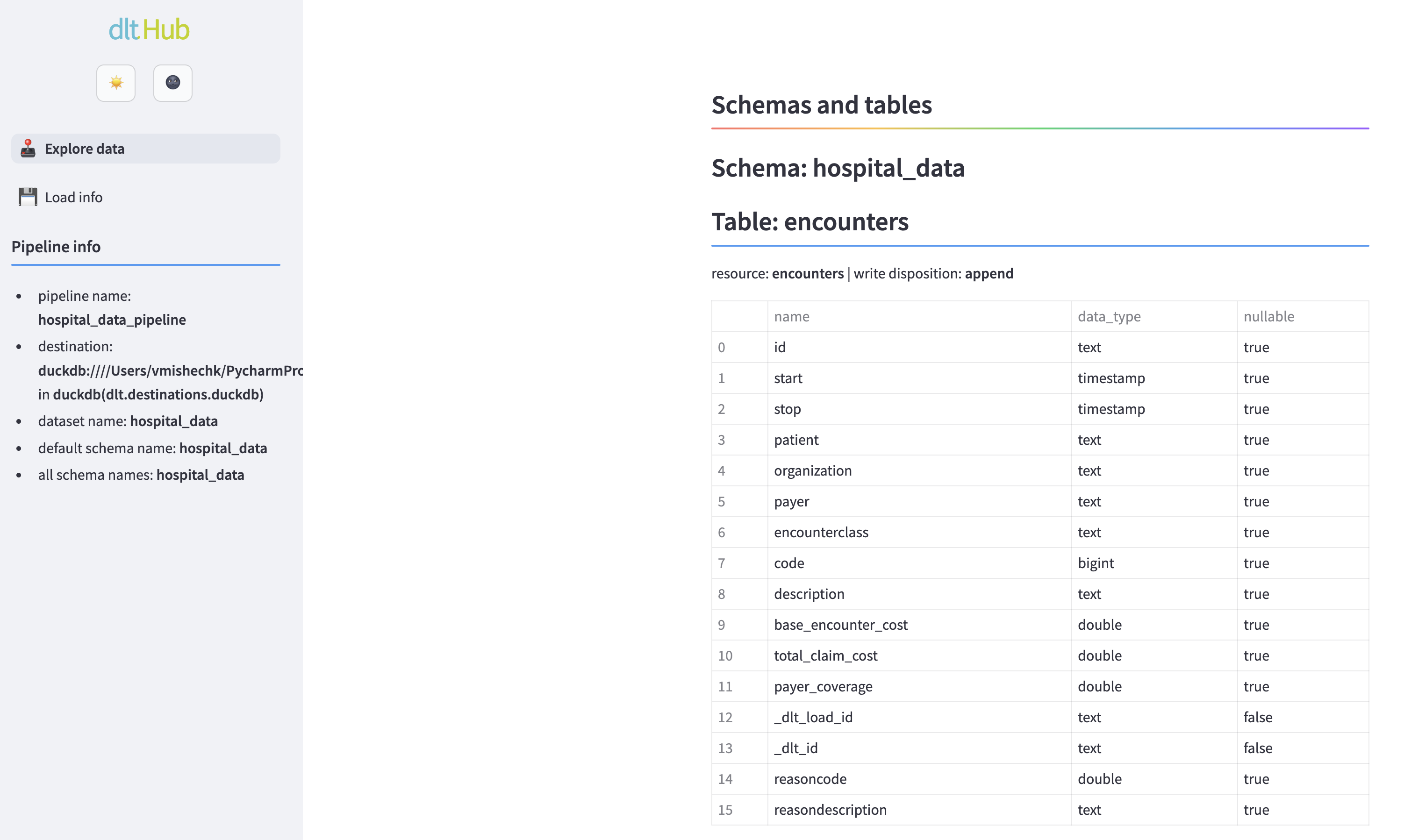
You can explore the loaded data, run queries, and see some pipeline execution details.
6. Appending, replacing, and merging loaded data
If you try running the pipeline again with python filesystem_pipeline.py, you will notice that all the tables have duplicated data. This happens because by default, dlt appends the data to the destination table. It is very useful, for example, when you have daily data updates and you want to ingest them. With dlt, you can control how the data is loaded into the destination table by setting the write_disposition parameter in the resource configuration. The possible values are:
append: Appends the data to the destination table. This is the default.replace: Replaces the data in the destination table with the new data.merge: Merges the new data with the existing data in the destination table based on the primary key.
To specify the write_disposition, you can set it in the pipeline.run command. Let's change the write disposition to merge. In this case, dlt will deduplicate the data before loading them into the destination.
To enable data deduplication, we also should specify a primary_key or merge_key, which will be used by dlt to define if two records are different. Both keys could consist of several columns. dlt will try to use merge_key and fallback to primary_key if it's not specified. To specify any hints about the data, including column types, primary keys, you can use the apply_hints method.
import dlt
from dlt.sources.filesystem import filesystem, read_csv
files = filesystem(file_glob="encounters*.csv")
reader = (files | read_csv()).with_name("encounters")
reader.apply_hints(primary_key="id")
pipeline = dlt.pipeline(pipeline_name="hospital_data_pipeline", dataset_name="hospital_data", destination="duckdb")
info = pipeline.run(reader, write_disposition="merge")
print(info)
You may need to drop the previously loaded data if you loaded data several times with append write disposition to make sure the primary key column has unique values.
You can learn more about write_disposition in the write dispositions section of the incremental loading page.
7. Loading data incrementally
When loading data from files, you often only want to load files that have been modified. dlt makes this easy with incremental loading. To load only modified files, you can use the apply_hint method:
import dlt
from dlt.sources.filesystem import filesystem, read_csv
files = filesystem(file_glob="encounters*.csv")
files.apply_hints(incremental=dlt.sources.incremental("modification_date"))
reader = (files | read_csv()).with_name("encounters")
reader.apply_hints(primary_key="id")
pipeline = dlt.pipeline(pipeline_name="hospital_data_pipeline", dataset_name="hospital_data", destination="duckdb")
info = pipeline.run(reader, write_disposition="merge")
print(info)
Notice that we used apply_hints on the files resource, not on reader. As mentioned before, the filesystem resource lists all files in the storage based on the file_glob parameter. So at this point, we can also specify additional conditions to filter out files. In this case, we only want to load files that have been modified since the last load. dlt will automatically keep the state of the incremental load and manage the correct filtering.
But what if we not only want to process modified files but also want to load only new records? In the encounters table, we can see the column named STOP indicating the timestamp of the end of the encounter. Let's modify our code to load only those records whose STOP timestamp was updated since our last load.
import dlt
from dlt.sources.filesystem import filesystem, read_csv
files = filesystem(file_glob="encounters*.csv")
files.apply_hints(incremental=dlt.sources.incremental("modification_date"))
reader = (files | read_csv()).with_name("encounters")
reader.apply_hints(primary_key="id", incremental=dlt.sources.incremental("STOP"))
pipeline = dlt.pipeline(pipeline_name="hospital_data_pipeline", dataset_name="hospital_data", destination="duckdb")
info = pipeline.run(reader, write_disposition="merge")
print(info)
Notice that we applied incremental loading both for files and for reader. Therefore, dlt will first filter out only modified files and then filter out new records based on the STOP column.
If you run dlt pipeline hospital_data_pipeline show, you can see the pipeline now has new information in the state about the incremental variable:
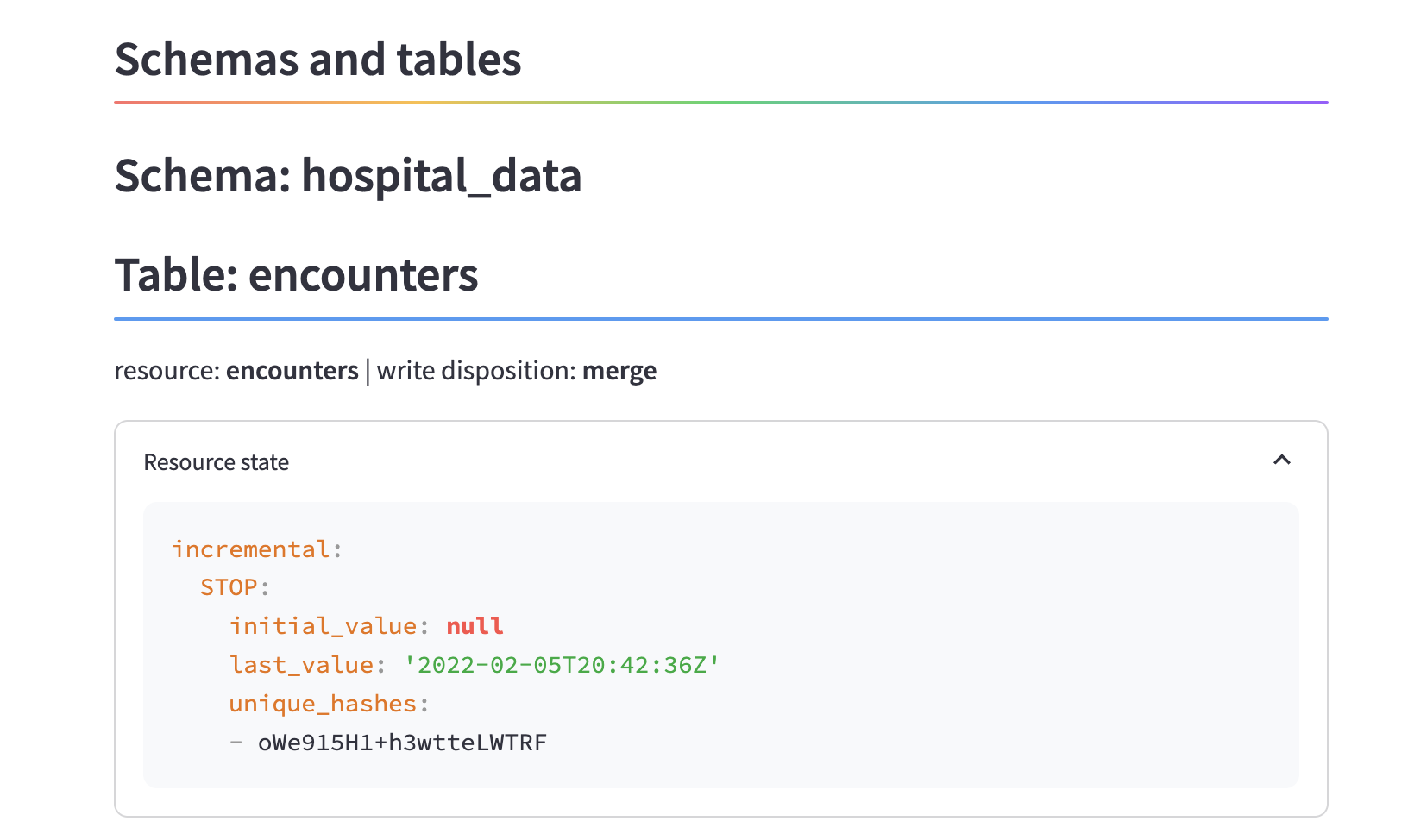
To learn more about incremental loading, check out the filesystem incremental loading section.
8. Enrich records with the files metadata
Now let's add the file names to the actual records. This could be useful to connect the files' origins to the actual records.
Since the filesystem source yields information about files, we can modify the transformer to add any available metadata. Let's create a custom transformer function. We can just copy-paste the read_csv function from dlt code and add one column file_name to the dataframe:
from typing import Any, Iterator
import dlt
from dlt.sources import TDataItems
from dlt.sources.filesystem import FileItemDict
from dlt.sources.filesystem import filesystem
@dlt.transformer()
def read_csv_custom(items: Iterator[FileItemDict], chunksize: int = 10000, **pandas_kwargs: Any) -> Iterator[TDataItems]:
import pandas as pd
# Apply defaults to pandas kwargs
kwargs = {**{"header": "infer", "chunksize": chunksize}, **pandas_kwargs}
for file_obj in items:
with file_obj.open() as file:
for df in pd.read_csv(file, **kwargs):
df["file_name"] = file_obj["file_name"]
yield df.to_dict(orient="records")
files = filesystem(file_glob="encounters*.csv")
files.apply_hints(incremental=dlt.sources.incremental("modification_date"))
reader = (files | read_csv_custom()).with_name("encounters")
reader.apply_hints(primary_key="id", incremental=dlt.sources.incremental("STOP"))
pipeline = dlt.pipeline(pipeline_name="hospital_data_pipeline", dataset_name="hospital_data", destination="duckdb")
info = pipeline.run(reader, write_disposition="merge")
print(info)
After executing this code, you'll see a new column in the encounters table:
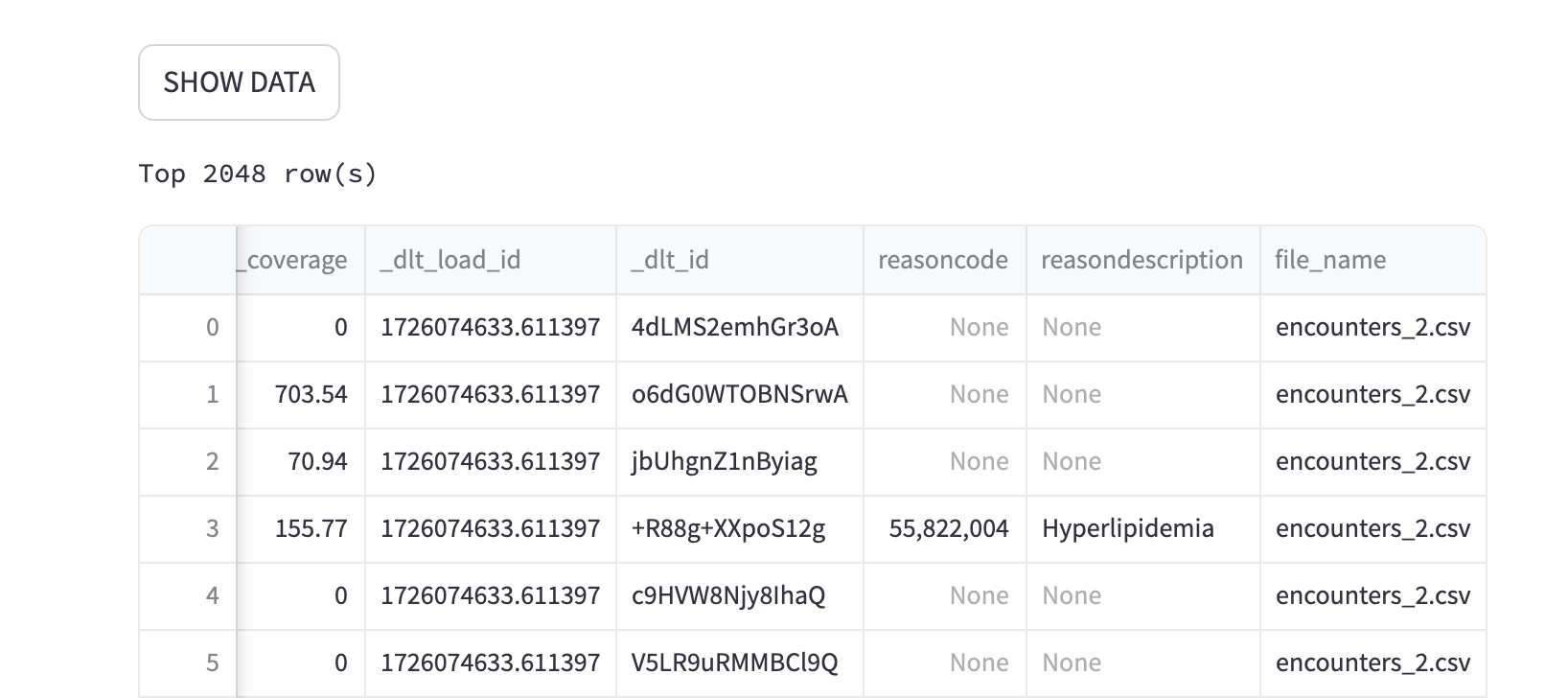
9. Load any other type of files
dlt natively supports three file types: CSV, Parquet, and JSONL (more details in filesystem transformer resource). But you can easily create your own. In order to do this, you just need a function that takes as input a FileItemDict iterator and yields a list of records (recommended for performance) or individual records.
Let's create and apply a transformer that reads JSON files instead of CSV (the implementation for JSON is a little bit different from JSONL).
from typing import Iterator
import dlt
from dlt.common import json
from dlt.common.storages.fsspec_filesystem import FileItemDict
from dlt.common.typing import TDataItems
from dlt.sources.filesystem import filesystem
# Define a standalone transformer to read data from a JSON file.
@dlt.transformer(standalone=True)
def read_json(items: Iterator[FileItemDict]) -> Iterator[TDataItems]:
for file_obj in items:
with file_obj.open() as f:
yield json.load(f)
files_resource = filesystem(file_glob="**/*.json")
files_resource.apply_hints(incremental=dlt.sources.incremental("modification_date"))
json_resource = files_resource | read_json()
pipeline = dlt.pipeline(pipeline_name="s3_to_duckdb", dataset_name="json_data", destination="duckdb")
info = pipeline.run(json_resource, write_disposition="replace")
print(info)
Check out other examples showing how to read data from excel and xml files.
What's next?
Congratulations on completing the tutorial! You've learned how to set up a filesystem source in dlt and run a data pipeline to load the data into DuckDB.
Interested in learning more about dlt? Here are some suggestions:
- Learn more about the filesystem source configuration in filesystem source
- Learn more about different credential types in Built-in credentials
- Learn how to create a custom source in the advanced tutorial